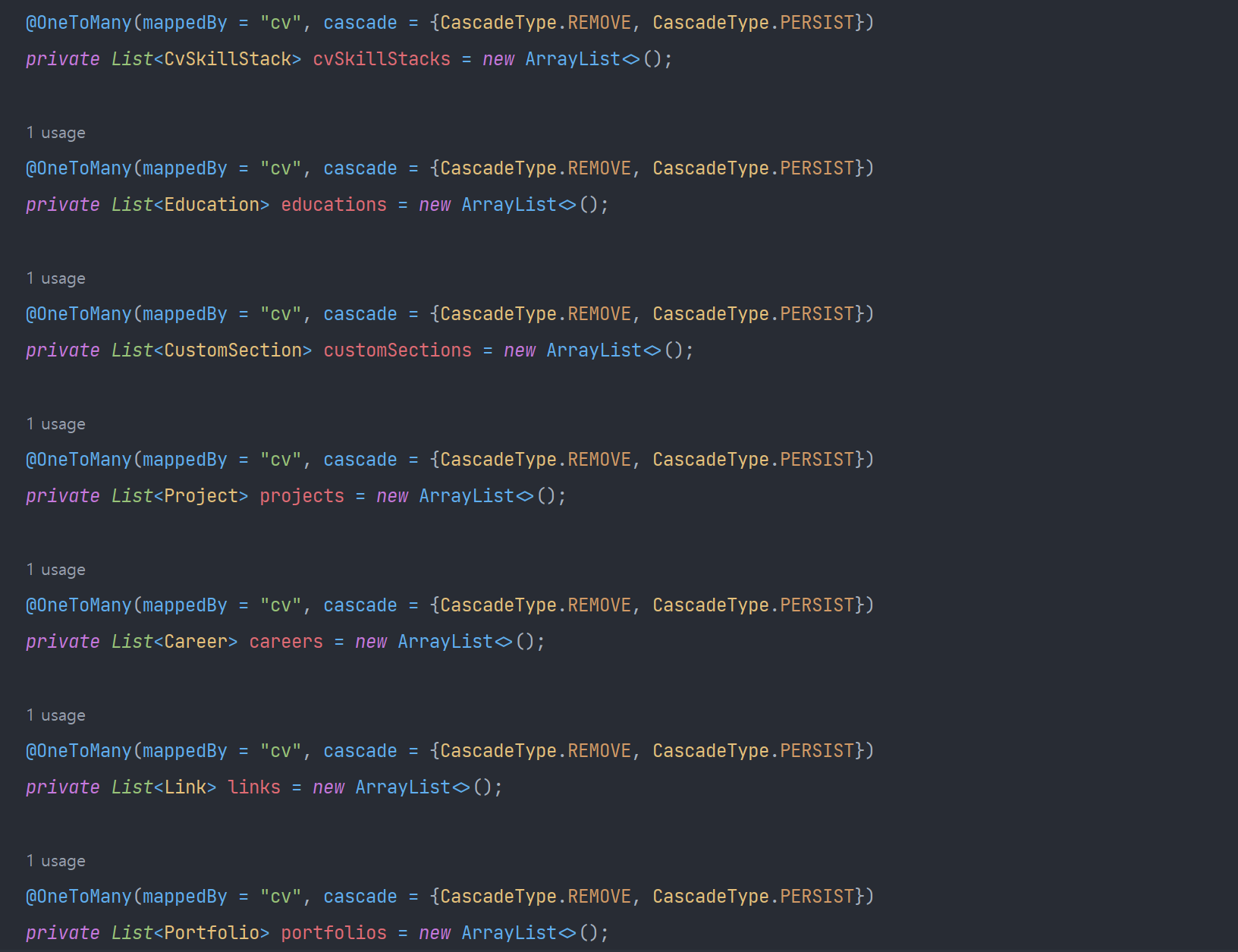
위 로직은 이력서 도메인과 1:N 관계의 entity들이다. 1개의 이력서에는 기술 스택, 교육 사항, 프로젝트, 경력 등을 여러 개 입력할 수 있다. 여기서 하나의 이력서(CV)를 조회할 때, N+1 문제가 발생하는 것을 확인했다. 로그를 보면, 하나의 이력서(CV)를 조회하는 쿼리가 날아가고 추가적으로 연관된 객체들이 조회되는 것을 확인할 수 있다. 만약 여러 개의 이력서를 조회한다고 가정하고 이력서의 개수가 N개라면 N * (1 + 8)개의 쿼리가 발생한다. 극단적으로 예를 들면 10000개의 이력서가 있고 findAll()로 이력서들을 조회하면 90000개의 쿼리가 발생할 것이다. 따라서 1번의 쿼리에 N번의 쿼리가 추가 실행되므로, 쿼리 실행 횟수가 증가하여 성능에 부담을 주고 데이터베이스에 부..